Kimi K2.5 Use Cases 2026: Where It Beats Claude and Codex
Most model comparison posts answer the wrong question.
In real teams, the question is simpler: "Which model should we use for this task right now?" This guide is built around that.
TL;DR#
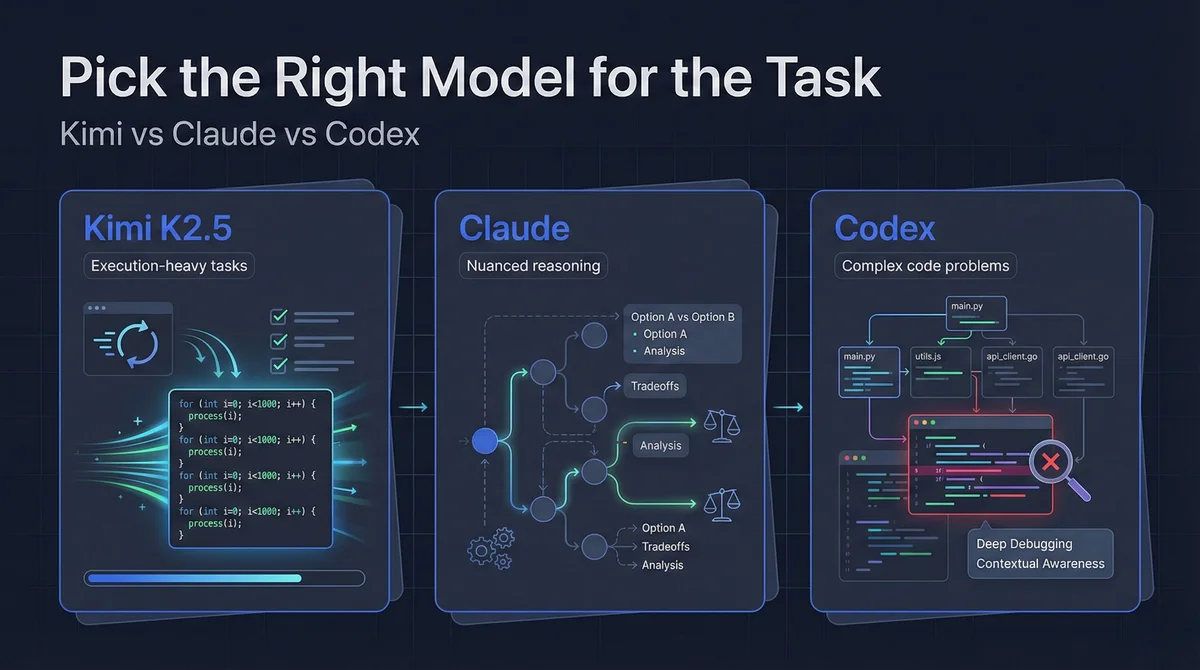
- Start with Kimi K2.5 for constrained, repetitive, easy-to-validate work.
- Start with Claude for ambiguity, architecture tradeoffs, and risk-heavy reasoning.
- Start with Codex for deep debugging, edge-case implementation, and large-context code changes.
- Pick by task type, not by model loyalty.
If you want background first, start with Kimi vs Claude Sonnet 4.5, Claude Opus 4.6 vs Codex 5.3, and my budget coding LLM analysis.
Quick pick in 30 seconds#
| Your Task | Best First Pick | Why This Usually Works | Switch If |
|---|---|---|---|
| Mechanical refactor across many files | Kimi K2.5 | Fast throughput and good structure following | You hit subtle regressions or unclear behavior |
| Test suite expansion | Kimi K2.5 | Cheap iteration and consistent test pattern generation | Failing tests need deeper root-cause reasoning |
| Architecture decision under uncertainty | Claude | Better at exposing assumptions and tradeoffs | Decision becomes mostly implementation detail |
| Deep multi-file bug hunt | Codex | Strong code-level tracing across modules | The issue is mostly product ambiguity, not code complexity |
| High-risk production patch | Claude or Codex | Reliability matters more than model cost | Scope shrinks into routine, low-risk edits |
Cost comparison snapshot (API pricing, February 7, 2026)#
If you care about cost-performance, token pricing changes the decision fast.
Here is a practical snapshot using published API rates and common model stats:
Kimi K2.5 vs Claude vs Codex: API Cost Snapshot
| Model | Context | Input / 1M | Output / 1M | Cached Input / 1M | Max Output | Input+Output / 1M |
|---|---|---|---|---|---|---|
| 🥇 Kimi K2.5 (Moonshot API) | 256K | $0.60 | $3.00 | $0.10 | N/A | $3.60 |
| 🥈 Claude Sonnet 4.5 | 200K (1M beta) | $3.00 | $15.00 | $0.30 | 64K | $18.00 |
| 🥉 Claude Opus 4.6 | 200K (1M beta) | $5.00 | $25.00 | $0.50 | 128K | $30.00 |
| ⚙️ GPT-5-Codex (closest API baseline) | 400K | $1.25 | $10.00 | $0.125 | 128K | $11.25 |
On these rates, Kimi is usually much cheaper for routine high-volume work, while Claude and Codex can still be worth the premium when the failure cost is high.
Note: Kimi K2.5 pricing here is from Moonshot's official forum launch post image and can change. Always check current dashboard rates before committing budgets.
Where Kimi actually saved me time (and money)#
Kimi K2.5 is what I reach for when I already know the shape of the answer and mainly need speed.
The pattern I keep seeing is not "smartest model wins." It is "fastest acceptable output wins."
For most routine engineering tasks, Kimi is good enough and noticeably cheaper than Sonnet, Opus, or Codex.
In practice, that gives two concrete wins:
- Time: faster first drafts and faster iteration loops on constrained tasks.
- Money: materially lower spend when output can be validated quickly.
1) Large, mechanical refactors#
When a change is repetitive and scoped, Kimi is often the best first pass.
Think rename patterns, interface alignment, or repeated structure updates. If I can define clear constraints and review with predictable checks, Kimi is hard to beat on cost-performance.
2) Test expansion for known behavior#
For regression tests and edge-case coverage around existing functionality, Kimi is often enough.
I use it to expand cases quickly, then run tests and tighten failures manually. For this class of work, iteration speed matters more than first-pass elegance.
3) Integration scaffolding and diff-based docs#
Typed adapters, wrappers, and migration summaries are usually structured tasks, which is exactly where Kimi tends to do well.
If the output format is explicit, it can produce useful drafts fast. That includes changelogs, upgrade notes, and first-pass incident writeups.
In practice, Kimi works best when validation is straightforward and errors are cheap to catch.
Where I still pick Claude first#
Claude is my default when the biggest risk is a bad decision, not a slow draft.
1) Architecture and system tradeoffs#
If a decision can create months of maintenance cost, I start with Claude.
It is better at surfacing hidden assumptions, second-order effects, and "this looks fine now but hurts later" tradeoffs.
2) Ambiguous requirements#
When product asks for something fuzzy or conflicting, Claude usually helps untangle intent faster.
That matters because the wrong interpretation at the start is often more expensive than slower implementation later.
3) Rollout strategy and risk framing#
For staged rollouts, guardrail design, and failure-mode mapping, Claude is usually safer.
This is where I want structured reasoning quality more than generation speed.
My rule of thumb: pick Claude first when uncertainty and failure cost are both high.
Where Codex still wins for me#
Codex earns its keep when code-level difficulty is the bottleneck.
1) Deep bug hunts across module boundaries#
When failures are spread across multiple services or layers, Codex is often stronger at narrowing the real fault line.
I reach for it when I need precision, not broad brainstorming.
2) Edge-case-heavy implementation#
Parser logic, boundary conditions, strict typing edges, and brittle integrations usually reward Codex-level precision.
This is especially true when "almost correct" still means broken production behavior.
3) Large-context implementation changes#
When a change needs deep understanding across many files, Codex is often the strongest first model.
That makes it useful for hard refactors where local correctness is not enough and cross-module consistency matters.
Rule of thumb: pick Codex first when the complexity lives in the code, not the requirements.
How I choose in practice#
This is the checklist I use in day-to-day work:
- Define the task class: constrained execution, ambiguous reasoning, or deep code complexity.
- Estimate failure cost: annoying, expensive, or dangerous.
- Choose first model: Kimi for constrained work, Claude for ambiguity, Codex for deep complexity.
- Run a small probe task before full scope.
- Switch models fast if output quality is below your acceptance bar.
This one habit removed most "which model should we use?" debates for me.
Common model-selection mistakes (and quick fixes)#
Even with a decent framework, teams still lose time and money in the same predictable ways. These are the mistakes I see most often.
- Using one model as the default for every task.
Quick fix: classify the task first (constrained, ambiguous, or code-complex), then pick the model. - Chasing low cost on high-risk work.
Quick fix: if failure is expensive, start with Claude or Codex and optimize spend later. - Overpaying for routine execution work.
Quick fix: start with Kimi for repetitive, easy-to-validate tasks and escalate only when needed. - Skipping validation loops and blaming model quality.
Quick fix: run small probes, define acceptance criteria, and switch quickly when outputs miss the bar. - Comparing models without a fixed task definition.
Quick fix: keep scope, constraints, and success criteria constant before judging model quality.
If you fix these five, model selection stops feeling random and starts working like an engineering decision.
Final recommendation#
Use Kimi K2.5 as your default executor for routine, constrained engineering tasks.
Use Claude for high-ambiguity reasoning and expensive-to-get-wrong decisions.
Use Codex for deep debugging and precision-heavy implementation paths.
If you apply this as a team policy, quality usually goes up and model spend usually goes down.